Гениально или глупо? Самая неоднозначная нейросеть
Некоторые считают нейронную сеть экстремального обучения (ELM) одной из самых удачных нейросетей — изучению её архитектуры даже посвящена отдельная конференция. Сторонники ELM утверждают, что для выполнения стандартных задач ей нужно в разы меньше времени и примеров. С другой стороны, хоть такие нейросети пока мало представлены в сфере машинного обучения, они уже подвергаются жёсткой критике со стороны экспертов, в том числе и Яна Лекуна: по их мнению, ELM явно не заслуживает того внимания и доверия, которое ей оказывают.
Чаще всего концепцию нейросети экстремального обучения считают интересной.
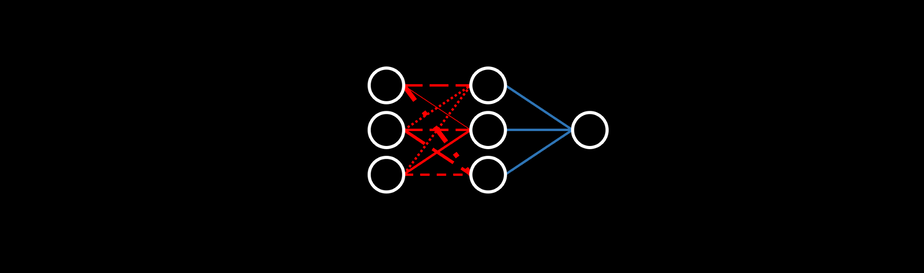
В архитектуру ELM входит два слоя: первый состоит из фиксированных и случайным образом инициализируемых значений, а второй способен обучаться. По сути, нейросеть случайным образом проецирует данные в новое место и производит множественную регрессию (а затем, конечно, передаёт результат функции активации на выходе). Произвольная проекция подразумевает использование метода снижения (или увеличения) размерности, который умножает случайные матрицы на вход. Хотя такая идея может показаться странной, но беспорядочное извлечение данных из стратегического распределения может очень даже хорошо работать (и в дальнейшем мы с вами убедимся в этом). Оно использует случайные искажения, подобные шумам, которые при правильном их применении позволяют остальной нейросети адаптироваться, открывая новые возможности для обучения.
Именно благодаря этой произвольности нейросети экстремального обучения с относительно небольшими узлами в скрытом слое соответствуют теореме Цыбенко.
Randomly initialized, Fixed (cannot be trained) - Инициализируемый случайным образом, фиксированный слой (без возможности
обучения)
Trained - Слой обучения
Произвольные проекции (как они в то время назывались) в сфере разработки нейронных сетей были исследованы давно, в 1980–1990 годах. Поэтому критики говорят, что в нейросетях экстремального обучения нет ничего нового — это просто старые исследования под новым названием. В других архитектурах, например, в сетях эхо- и неустойчивых состояний, также используются случайные переходные связи и другие генераторы произвольности.
Нейросети экстремального обучения не используют алгоритм обратного распространения ошибки, и в этом состоит их наиболее значимое отличие от других нейронных сетей. Поскольку обучаемая часть нейросети представляет собой просто-напросто множественную регрессию, параметры обучаются примерно так же, как коэффициенты включаются в регрессию. Это коренным образом меняет представление о процессе обучения нейронных сетей.
Большинство нейросетей усовершенствовалось после того, как путём итеративных корректировок (или отладки, если хотите) были оптимизированы стандартные нейронные сети. Эти корректировки предполагали передачу информационных сигналов в разных направлениях по сети. Так как этот метод уже давно в ходу, можно подумать, что он лучший, ведь его опробовали множество раз. Однако исследователи утверждают, что у алгоритма обратного распространения ошибки много недочётов, к примеру низкая скорость обучения или приведение к очень уж заманчивым локальным минимумам.
С другой стороны, в ELM используется гораздо более выверенная в математическом плане формула установки весов. Не углубляясь в математику, можно понять, что слой случайных значений компенсирует более сложные вычисления, которые могли бы быть на его месте. Строго говоря, крайне популярный нынче слой исключения (dropout) — это тоже своего рода произвольная проекция.
Поскольку в нейросетях экстремального обучения используются и случайность, и алгоритм, противоположный алгоритму обратного распространения ошибки, такие сети обучаются в разы быстрее стандартных нейронных сетей. Производительнее они или нет — уже другой вопрос.
Кто-то может поспорить, что нейросети экстремального обучения лучше воспроизводят процесс обучения человека, чем стандартные (хотя и те, и другие далеки от этого), поскольку могут решать простые задачи быстрее, обучившись всего на нескольких примерах, в то время как итеративным сетям для хорошей производительности нужны десятки тысяч примеров. В сравнении с нейросетями у людей могут быть недостатки, однако наше ощутимое превосходство в соотношении “обучение — примеры” (примеры — количество представленных обучающих ситуаций) — это именно то, что делает нас по-настоящему разумными.
Принцип устройства ELM очень простой, настолько простой, что некоторые даже считают его глупым. Ян Лекун, известный учёный в области компьютерных наук и основоположник глубокого обучения, заявил, что “произвольное присоединение первого слоя — самое элементарное, что только можно сделать”. В защиту своей точки зрения он перечислил более продвинутые средства нелинейного преобразования размерности векторов, такие как ядерные методы, применяемые в нейросетях с методом опорных векторов (SVM) и усиливаемые с помощью алгоритма обратного распространения ошибки.
Лекун говорит, что экстремальное обучение — это, по сути, тот же метод опорных векторов, но с худшим ядром преобразования. Решения для ограниченного числа задач, которые могут предложить ELM, могли бы быть гораздо лучше смоделированы SVM. Единственный контраргумент здесь — использование “произвольного ядра” более эффективно с вычислительной точки зрения, чем использование специализированных ядер, ведь SVM известен своей высокой мощностью. Применение нейросети экстремального обучения может повлечь за собой снижение производительности, поэтому целесообразность её использования — ещё один открытый вопрос.
SVM - Нейросеть с методом опорных векторов
ELM - Нейросеть экстремального обучения
Input - Вход
Output - Выход
Transformation kernel (polynomial, etc.) - Ядро преобразования (полиномиальное и др.)
Random kernel - Произвольное ядро
Linear optimization - Линейная оптимизация
Нравятся вам нейросети экстремального обучения или нет, опыт показывает, что применение произвольных проекций или фильтров в простых нейронных сетях и других моделях показало на удивление хорошие результаты при выполнении стандартных (сейчас бы их назвали “простыми”) задач, например, на наборе данных MNIST. И хотя их производительность не самая лучшая, тот факт, что архитектура, которая привлекла настолько пристальное внимание (в том числе и принципом своего устройства, кажущимся почти глупостью) стоит в одном ряду с самыми продвинутыми нейросетями (в том числе, с облегчёнными и более энергоэффективными архитектурами), — это что-то, что заслуживает, как минимум, интереса.
Почему фиксированные произвольные связи работают?
Это вопрос на миллион: очевидно, что произвольные связи в ELM как-то да работают, если производительность сети такая же, а то и лучше, чем у стандартных нейросетей с алгоритмом обратного распространения ошибки. Пусть математика, которая за этим стоит, неочевидна, автор первого труда по нейросетям экстремального обучения, Гуан-Бин Хуан, описал принцип их работы аллегорически (адаптировано для читабельности, лаконичности и проведения чётких параллелей с глубоким обучением):
Вам нужно наполнять озеро камнями вместо воды до тех пор, пока поверхность не станет ровной. У пустого озера видно дно, которое является кривой (функция, представляющая данные). Инженер обстоятельно вычисляет размеры озера и камней, просчитывает множество мелких факторов, каждый из которых играет свою роль в оптимизации задачи (оптимизация множества параметров, которые соответствуют функции).
Floor of lake - Дно озера
Stones - Камни
Level line - Линия уровня
С другой стороны, есть фермер, который взрывает находящуюся поблизости гору и сталкивает упавшие с неё камни в озеро. Когда фермер берёт камень (узел скрытого слоя), ему не нужно знать ни размеры озера, ни размеры камня — он просто бросает камни в случайном порядке и распределяет по дну. Если где-то камни начинают выступать за линию уровня, фермер просто берёт кувалду и вбивает их (бета-параметр — регуляризация сортировки), выравнивая поверхность.
В то время как инженер всё ещё занят вычислением высоты и объёма камней и формы озера, фермер это озеро уже наполнил. Для фермера не имеет значения, сколько понадобилось камней — он закончил работу быстрее.
Хотя прямое применение такой аналогии к различным случаям может быть проблематичным, она понятно описывает природу ELM и роль случайности в обучении модели. Смысл нейросетей экстремального обучения состоит в том, что примитивность — это не всегда плохо: более простые решения могут лучше подходить для несложных задач.
Основные моменты
- В нейросетях экстремального обучения используется фиксированный первый слой из случайных значений и обучающийся второй слой. По сути, это произвольная проекция, за которой следует множественная регрессия.
- Сторонники ELM утверждают, что в простых случаях (например, при использовании MNIST) такая нейросеть способна обучаться быстро на меньшем количестве примеров. Преимущества ELM: её очень легко программировать, нет необходимости выбирать такие параметры, как архитектура, оптимизаторы, коэффициент потерь. С другой стороны, по мнению противников ELM, в таких случаях целесообразнее использовать нейросеть с методом опорных векторов, ELM не подходит для решения более сложных задач и является попросту переосмыслением очень старой идеи.
- ELM, как правило, не очень хорошо показывает себя на сложных задачах, но то, что эта сеть демонстрирует хорошую производительность на более простых задачах, — веский повод поближе познакомиться с облегчёнными архитектурами, моделями без алгоритма обратного распространения ошибки и произвольными проекциями. По крайней мере, нейросети экстремального обучения (называйте лежащую в их основе идею, как хотите) — любопытное явление, о котором должен знать любой интересующийся глубоким обучением специалист.
Перевод статьи Andre Ye: Some Call it Genius, Others Call it Stupid: The Most Controversial Neural Network Ever Created
Комментарии