Как организовать код в Python
Если вы занимаетесь вычислительными исследованиями или наукой о данных, но у вас нет опыта в области компьютерных наук, то вы, вероятно, создали удивительные научные данные, но написанный для этого код не позволит достичь академического успеха. Даже опытному программисту трудно выполнять работу как разработчика, так и ученого.
В этой статье я расскажу о том, как организовать рабочий процесс написания кода, дам несколько советов и покажу набор инструментов для работы. Цель состоит в том, чтобы облегчить переход от экспериментов к разработке инструментов.
Jupyter Notebook: цифровая лабораторная тетрадь
Для обеспечения воспроизводимости исследований необходимо регистрировать все, что вы делаете. Это достаточно обременительно, особенно если вы просто хотите просто поэкспериментировать и выполнить специальный анализ.
Отличный инструмент для экспериментов — Jupyter Notebook. Интерактивный интерфейс программирования позволяет мгновенно проверять действия, выполняемые кодом, благодаря чему можно создавать алгоритмы шаг за шагом. Более того, вы можете использовать ячейки Markdown для записи своих идей и выводов одновременно с кодом.
В интернете можно найти множество руководств по Jupyter. Рекомендую ознакомиться с горячими клавишами, поскольку они значительно ускоряют работу.
Эксперименты с циклом for
В цифровом виде выполнение цикла по экспериментальным переменным представляет собой действительно простой процесс. В конце концов, мощь компьютеров — это их способность повторять определенные действия.
Я структурирую формальные эксперименты следующим образом:
treatments = ['control', 't1', 't2']
subjects = ['A', 'B', 'C']
def experiment_with(subject, treatment):
# код эксперимента размещается здесь
return result
for t in treatments:
for s in subjects:
result = experiment_with(s, t)
# другие детали, такие как создание визуализаций
Для обеспечения прозрачности я сохраняю все важные переменные для текущего эксперимента в списках в начале файла.
Теперь необходимо определиться, что делать с выходными данными каждой итерации: создать из них визуализации, вычислить метрику или сохранить их? Выбор зависит от применения и желаемой формы отчетности.
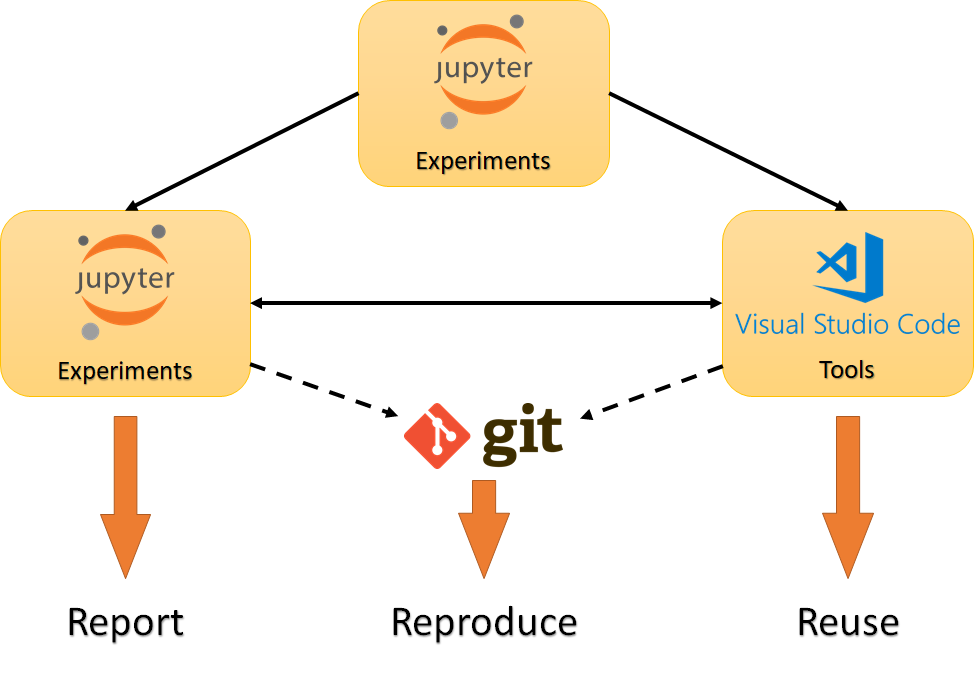
Централизация и перекрестные ссылки
Файл Notebook должен быть создан для каждой важной части эксперимента. Я сохраняю эксперимент с соответствующим заголовком и номером версии каждый раз, когда повторяю его с использованием разных параметров или нового способа выполнения действий.
В отличие от контроля версий в этом случае сохраняются все записи работы, а не только последняя версия. Все эксперименты я помещаю в одну папку независимо от того, к какому проекту они принадлежат.
Пример организации экспериментов в одной папкеВ результате получаем огромную кучу файлов, которую можно отсортировать по дате изменения. Благодаря централизации конкретные файлы можно с легкостью находить с помощью простого поиска.
Главным преимуществом такого объединения является возможность реализовать перекрестные ссылки внутри и между notebooks. Выполнить это можно с помощью HTML-ссылок в Markdown.
Чтобы создать ссылку на раздел в Notebook, добавьте следующий код в ячейку Markdown перед ссылочной частью:
<a id='label_of_your_choice'></a>
<!--ссылка в файле experiment00.ipynb-->
Теперь в том месте, где должна появиться ссылка на предыдущий источник, напишите один из следующих вариантов:
[description](#label_of_your_choice) <!--to make link in the same notebook-->
[description](experiment00.ipynb#label_of_your_choice) <!--делаем ссылку на другой файл-->
Например, [previous experiment](experiment00.ipynb#label_of_your_choice) выдает ссылку:
Теперь с помощью одного нажатия мыши можно перейти к указанному разделу в предыдущем эксперименте.
Отчеты должны содержать лучшие версии экспериментов и сопутствующие комментарии. Быстрый просмотр записей является ключом к повторяемости работы.
Работа с данными
Иногда результаты некоторых данных нужно сохранить для отчетов, обмена или использования в других экспериментах. Для таких случаев я сохраняю данные в папке данных, находящейся в папке экспериментов, и даю им название, проясняющее эксперимент, из которого они были взяты, и номер версии этого эксперимента.
Для лучшего понимания я веду журнал в электронной таблице, в котором перечислены входные и выходные данные всех экспериментов.
Функциональность пакетирования
Скорее всего, вы знакомы с написанием функций внутри сценария для улучшения чистоты и понятности кода, а также обеспечения выполнения принципа DRY (не повторяйтесь). По мере развития экспериментов, то же самое происходит и с функциями, которые содержат все больше логики и других функций.
Если вы следовали предыдущим советам, то начали разделять эксперименты на несколько файлов notebook: по одному для каждого эксперимента и его версии. Когда количество функций, выполняемых от одного эксперимента к другому, значительно увеличивается, приходит время задуматься о возможности повторного использования кода. Разве не было бы здорово, если бы была возможность просто импортировать функции, прошедшие проверку временем, в код, как это делается с любой другой библиотекой Python?
Начните с сохранения функций в файлах .py вместе с экспериментами. Вы можете редактировать эти файлы в любой IDE (я использую VS Code). Затем просто используйте оператор импорта с названием файла, чтобы вернуть эту функциональность в эксперименты:
# если сохранить функцию experiment_with() в
# файле experiment_functions.py в папке, в которой
# находится эксперимент, ее можно импортировать в код
from experiment_functions import experiment_with
Значения по умолчанию, скрывающие сложность
По мере роста сложности и гибкости, функции нуждаются в большем количестве входных данных, которыми трудно управлять. К счастью, Python облегчает установку значений по умолчанию для аргументов функций. Наличие значений по умолчанию значительно ускоряет процесс экспериментов, скрывая ненужную сложность. Более того, новичок, приступающий к работе над функциями, сможет разобраться в них гораздо быстрее.
Иногда встречаются такие ситуации, когда значение по умолчанию должно быть определено как функция других параметров. В этом случае я устанавливаю значение по умолчанию на None и проверяю в теле функции, был ли аргумент при вызове определен. Если этого не произошло, то присваиваю ему соответствующее значение. Пример:
def do_some_magic(a=10, b=None):
# если "b" не определен при вызове, ему присваивается значение по умолчанию, которое зависит от "a"
if b is None:
b = 10*a
# какие-либо действия
Объектно-ориентированное программирование для повышения гибкости
Для больших функций, инкапсулирующих целые алгоритмы с большим количеством параметров, простого интерфейса функции может быть недостаточно. В этой ситуации я предпочитаю гибкость объектно-ориентированного подхода.
При наличии алгоритмов, обернутых как объекты, можно изменять параметры на ходу, определяя их в качестве атрибутов класса. Просто настройте определенные конфигурации и при необходимости вносите лишь небольшие изменения в алгоритм.
class MagicAlgorithm(object):
# настройте параметры алгоритма
# в методе класса init; установите значения по умолчанию
# так же, как и для функций
def __init__(self, a=10, b=None):
if b is None:
b = 10*a
# получить доступ к параметрам в методах класса
# можно через аргумент self
def do_some_magic(self):
a_local = self.a
b_local = self.b
# какие-либо действия
# вы можете создать объекты алгоритма с определенной конфигурацией
# и вносить изменения параметров на ходу в рамках экспериментов
b_values = [1, 2, 3]
magicAlg = MagicAlgorithm(a=20) # создание экземпляра алгоритма
for b in b_values:
magicAlg.b = b # изменение лишь некоторых параметров
magicAlg.do_some_magic() # использование функциональности класса
Классы также можно использовать для создания специфичных для приложения структур данных и инкапсулирования связанной с ними функциональности. Существует целая наука о шаблонах проектирования с использованием ООП.
Контроль версий с сохранением воспроизводимости результатов
Когда повторно используемые функции находятся в модулях отдельно от кода эксперимента, обеспечение управляемости и воспроизводимости становится сложной задачей. Вероятно, со временем появится необходимость улучшить эти повторно используемые единицы кода.
Именно в этот момент воспроизводимость и возможность повторного использования вступают в противоречие. При воспроизведении двухлетнего эксперимента с помощью супер развитого алгоритма могут получиться абсолютно другие результаты. Допустим, вы хотите сохранить точную версию модулей, используемых в экспериментах, вместе с файлами notebook, в которых они были использованы (если вы не хотите скрыть какую-либо глупость, сделанную в прошлом). Сохранение пронумерованного файла для каждой внесенной модификации вместе с экспериментами для записи делает ситуацию еще более запутанной.
Введите контроль версий. Инженеры-программисты обеспечивают воспроизводимость с помощью управления версиями и использования сред для обеспечения совместимости. Этот подход можно применить и к экспериментам. Контролируйте версии функций и классов по мере их улучшения и в то же время сохраняйте ссылку на соответствующие версии в файлах эксперимента.
Я делаю это следующим образом: сортирую .py файлы в папки проектов с названием <project>_func, в которых устанавливаю репозитории, и начинаю управление версиями с помощью git.
При каждом создании нового файла эксперимента, я проверяю, зафиксирована ли используемая версия кода, и записываю следующие строки в верхнюю ячейку файла эксперимента:
%%bash
cd <project>_func # заходим в директорию, в которой находится
# необходимый репозиторий
git checkout <git commit id> # восстанавливаем версию кода,
# которая будет использоваться
В эксперименте я импортирую функции по мере необходимости. Допустим, я недавно переехал во Францию, и теперь пишу все отчеты на французском языке. Импорт и запуск последней версии этой функции:
from magic_func.magic import do_some_magic
do_some_magic()
Получаем:
Salut Le Monde!Проблема заключается в необходимости перезапустить старый сценарий эксперимента, который генерировал отчет на английском языке. К счастью, я ссылался на id коммита в верхней части notebook эксперимента, как было показано ранее:
%%bash
cd magic_func
git checkout cff052f7c36bb09ccc101d9ce3652dce87f2acbc
Вывод кода, показанного выше, в этом контексте выглядит следующим образом:
Hello World!Вуаля! Волшебство контроля версий и хорошо прописанных записей.
Использование пакетов Python для обмена
В конце концов, появится необходимость упаковать файлы .py вместе с соответствующими пакетами, чтобы поделиться ими с другими людьми и установить их в средах ядер Ipython, используемых в notebook экспериментов.
Следуйте официальному руководству по упаковыванию в Python, чтобы узнать, как упаковать код, и этому руководству, чтобы загрузить его на PyPi. Чтобы использовать определенную версию пакета в Jupyter Notebook, рекомендую установить его в среде conda. Чтобы запустить ядро Jupyter в этой среде, следуйте инструкциям по установке расширения nb_conda_kernels.
От экспериментов к модульному тестированию
По мере добавления функциональности в пакет вы можете принять философию разработки через тестирование, в которой говорится, что писать модульные тесты необходимо до написания тестируемого кода.
Создавать тесты можно прямо в Notebooks и просто вставлять их код в формальную структуру модульных тестов. Для своих пакетов я использую фреймворк pytest.
Если вы дошли до этой точки, то вы уже не просто экспериментатор. Вы также являетесь разработчиком, который может не только делиться созданными инструментами, а также поддерживать и улучшать их. Приятного программирования!
Перевод статьи Victor Serban: How to organize code in Python if you are a scientist
Комментарии