Шаблон Repository в Android
Вот 5 самых распространенных ошибок (некоторые из них также есть в официальной документации Android):
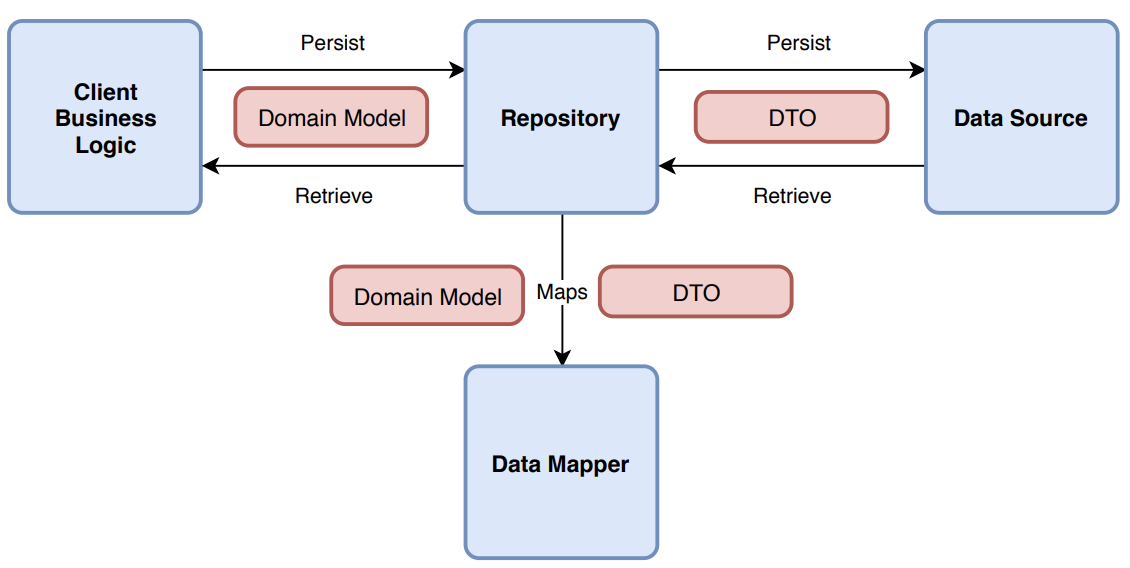
Как же правильно реализовать Repository?
Модель домена
Это ключевой момент в шаблоне, однако многие разработчики не понимают, что такое домен.
Цитируя Мартина Фаулера, можно сказать, что доменная модель — это:
Объектная модель домена, охватывающая поведение (функции) и свойства (данные).
Модели домена представляют корпоративные бизнес-правила. Существует 3 типа таких моделей:
В простых доменах эти модели очень схожи с моделями баз данных и сетей (DTO), однако они обладают несколькими различиями:
- Доменные модели объединяют данные и процессы. Их структура наиболее подходит для приложения.
- DTO — это представление объектной модели для запроса/ответа JSON/XML или таблицы базы данных, поэтому их структура является наиболее подходящей для удаленной коммуникации.
Пример модели домена:
// Сущность
data class Product(
val id: String,
val name: String,
val price: Price
) {
// Объект-значение
data class Price(
val nowPrice: Double,
val wasPrice: Double
) {
companion object {
val EMPTY = Price(0.0, 0.0)
}
}
}
Пример DTO:
// Сеть DTO
data class NetworkProduct(
@SerializedName("id")
val id: String?,
@SerializedName("name")
val name: String?,
@SerializedName("nowPrice")
val nowPrice: Double?,
@SerializedName("wasPrice")
val wasPrice: Double?
)
// База данных DTO
@Entity(tableName = "Product")
data class DBProduct(
@PrimaryKey
@ColumnInfo(name = "id")
val id: String,
@ColumnInfo(name = "name")
val name: String,
@ColumnInfo(name = "nowPrice")
val nowPrice: Double,
@ColumnInfo(name = "wasPrice")
val wasPrice: Double
)
Таким образом, доменная модель не зависит от фреймворков, а ее структура поддерживает многозначные атрибуты (логически сгруппированные в Price) и использует шаблон Null Object (поля non-nullable), тогда как DTO связаны с фреймворком (Gson, Room).
Благодаря этому разделению:
- Упрощается разработка приложения, поскольку не нужно проверять нулевые значения. Благодаря многозначным атрибутам не нужно отправлять модель целиком.
- Изменения в источниках данных не влияют на уровни выше.
- Отсутствуют избыточные модели.
- Плохие реализации бэкенда не влияют на уровни выше (представьте, что вам приходится выполнять 2 сетевых запроса, потому что бэкенд не может предоставить всю необходимую информацию за один раз. Позволите ли вы этой проблеме повлиять на всю базу кода?
Преобразователь данных (Data Mapper)
Здесь DTO преобразуются в доменные модели и обратно.
Поскольку большинство разработчиков считают это преобразование скучным и ненужным процессом, они предпочитают соединять всю базу кода, начиная от источников данных и заканчивая пользовательским интерфейсом, с DTO.В результате первые релизы выполняются быстрее. Но пропуск доменного слоя и связывание пользовательского интерфейса с источниками данных вместо размещения бизнес-правил и вариантов использования на уровне представления (например, шаблон Smart UI) приводит к некоторым ошибкам. Эти ошибки можно обнаружить только в продакшне (например, бэкенд отправляет null вместо пустой строки, а она генерирует NullPointerException).
Реализация преобразователей представляет собой скучный процесс, но их наличие гарантирует отсутствие сюрпризов из-за изменения в поведении источников данных. При отсутствии времени или желания создавать преобразователи можно воспользоваться фреймворками, такими как http://modelmapper.org/.
Поскольку я стараюсь не использовать фреймворки в реализации, чтобы избежать шаблонного кода, у меня есть универсальный интерфейс mapper для каждого преобразователя:
interface Mapper<I, O> {
fun map(input: I): O
}
А также набор универсальных ListMappers, благодаря которым не нужно реализовывать каждое преобразование списка в список:
// Non-nullable к Non-nullable
interface ListMapper: Mapper<List<I>, List<O>>
class ListMapperImpl<I, O>(
private val mapper: Mapper<I, O>
) : ListMapper<I, O> {
override fun map(input: List<I>): List<O> {
return input.map { mapper.map(it) }
}
}
// Nullable к Non-nullable
interface NullableInputListMapper: Mapper<List<I>?, List<O>>
class NullableInputListMapperImpl<I, O>(
private val mapper: Mapper<I, O>
) : NullableInputListMapper<I, O> {
override fun map(input: List<I>?): List<O> {
return input?.map { mapper.map(it) }.orEmpty()
}
}
// Non-nullable к Nullable
interface NullableOutputListMapper: Mapper<List<I>, List<O>?>
class NullableOutputListMapperImpl<I, O>(
private val mapper: Mapper<I, O>
) : NullableOutputListMapper<I, O> {
override fun map(input: List<I>): List<O>? {
return if (input.isEmpty()) null else input.map { mapper.map(it) }
}
}
Отдельная модель для каждого источника данных
Допустим, что для сети и базы данных используется одна и та же модель:
@Entity(tableName = "Product")
data class ProductDTO(
@PrimaryKey
@ColumnInfo(name = "id")
@SerializedName("id")
val id: String?,
@ColumnInfo(name = "name")
@SerializedName("name")
val name: String?,
@ColumnInfo(name = "nowPrice")
@SerializedName("nowPrice")
val nowPrice: Double?,
@ColumnInfo(name = "wasPrice")
@SerializedName("wasPrice")
val wasPrice: Double?
)
Изначально может показаться, что этот способ намного быстрее, чем создание двух разных моделей, однако такой подход предполагает определенный риск:
- Кэширование большего количества объектов, чем это необходимо.
- Добавление полей в ответ потребует переноса базы данных, если не добавить аннотацию
@Ignore. - Для всех кэшируемых полей, которые не нужно отправлять в качестве тела запроса, необходимо добавить аннотацию
@Transient. - Новые поля должны иметь один и тот же тип данных (например, мы не можем распарсить строку n
owPriceиз сетевого ответа и кэшироватьnowPriceдважды).
Таким образом, этот подход требует гораздо большей поддержки, чем отдельные модели.
Кэширование только по необходимости
Допустим, нужно отобразить список продуктов, хранящихся в удаленном каталоге, и для каждого продукта показать классический значок сердца, если он находится в локальном списке пожеланий.
Для этого нужно:
Доменная модель будет выглядеть как и прежде, однако с добавлением поля, в котором указано, есть ли товар в списке пожеланий:
// Сущность
data class Product(
val id: String,
val name: String,
val price: Price,
val isFavourite: Boolean
) {
// Объект-значение
data class Price(
val nowPrice: Double,
val wasPrice: Double
) {
companion object {
val EMPTY = Price(0.0, 0.0)
}
}
}
Сетевая модель будет выглядеть так же, а в модели базы данных просто нет необходимости. Хранить id продуктов для локального списка пожеланий можно в SharedPreferences. Не нужно усложнять логику и разбираться с переносами баз данных.
Репозиторий будет выглядеть следующим образом:
class ProductRepositoryImpl(
private val productApiService: ProductApiService,
private val productDataMapper: Mapper<DataProduct, Product>,
private val productPreferences: ProductPreferences
) : ProductRepository {
override fun getProducts(): Single<Result<List<Product>>> {
return productApiService.getProducts().map {
when(it) {
is Result.Success -> Result.Success(mapProducts(it.value))
is Result.Failure -> Result.Failure<List<Product>>(it.throwable)
}
}
}
private fun mapProducts(networkProductList: List<NetworkProduct>): List<Product> {
return networkProductList.map {
productDataMapper.map(DataProduct(it, productPreferences.isFavourite(it.id)))
}
}
}
Используемые зависимости можно описать так:
// Враппер для обработки неудачных запросов
sealed class Result<T> {
data class Success<T>(val value: T) : Result<T>()
data class Failure<T>(val throwable: Throwable) : Result<T>()
}
// DataSource для SharedPreferences
interface ProductPreferences {
fun isFavourite(id: String?): Boolean
}
// DataSource для удаленной БД
interface ProductApiService {
fun getProducts(): Single<Result<List<NetworkProduct>>>
fun getWishlist(productIds: List<String>): Single<Result<List<NetworkProduct>>>
}
// Кластер DTO для отображения в Product
data class DataProduct(
val networkProduct: NetworkProduct,
val isFavourite: Boolean
)
Но если нужно получить только те продукты, которые относятся к списку пожеланий? В этом случае будет схожая реализация:
class ProductRepositoryImpl(
private val productApiService: ProductApiService,
private val productDataMapper: Mapper<DataProduct, Product>,
private val productPreferences: ProductPreferences
) : ProductRepository {
override fun getWishlist(): Single<Result<List<Product>>> {
return productApiService.getWishlist(productPreferences.getFavourites()).map {
when (it) {
is Result.Success -> Result.Success(mapWishlist(it.value))
is Result.Failure -> Result.Failure<List<Product>>(it.throwable)
}
}
}
private fun mapWishlist(wishlist: List<NetworkProduct>): List<Product> {
return wishlist.map {
productDataMapper.map(DataProduct(it, true))
}
}
}
Перевод статьи Denis Brandi: The “Real” Repository Pattern in Android
Комментарии