Python-библиотеки интерпретации моделей ML
Все эти библиотеки устанавливаются через pip и сопровождаются подробной документацией. Акцент в них делается на визуализацию.
Yellowbrick
Yellowbrick — это расширение scikit-learn, которое позволяет использовать полезные и красивые визуализации для моделей машинного обучения. Объекты визуализатора и интерфейс ядра — это функции оценки scikit-learn. Если ранее вы работали с данной библиотекой, то рабочий процесс будет вам знаком. Визуализации отображают выбор модели, важность признаков и анализ производительности. Далее небольшие примеры.
Рассмотрим некоторые возможности на примере датасета распознания вин в scikit-learn. В него входит 13 признаков и 3 целевых класса, которые могут быть загружены напрямую из scikit-learn. В коде ниже датасет импортируется и преобразуется в таблицу данных. Данные могут использоваться в классификаторе без предварительной обработки:
import pandas as pd
from sklearn import datasets
wine_data = datasets.load_wine()
df_wine = pd.DataFrame(wine_data.data,columns=wine_data.feature_names)
df_wine['target'] = pd.Series(wine_data.target)
Через scikit-learn можно запустить проверку данных и обучение:
from sklearn.model_selection import train_test_split
X = df_wine.drop(['target'], axis=1)
y = df_wine['target']
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2)
Посмотрим на корреляции между признаками:
from yellowbrick.features import Rank2D
import matplotlib.pyplot as plt
visualizer = Rank2D(algorithm="pearson", size=(1080, 720))
visualizer.fit_transform(X_train)
visualizer.poof()
Теперь подключим RandomForestClassifier и представим анализ данных в другом визуализаторе:
from yellowbrick.classifier import ClassificationReport
from sklearn.ensemble import RandomForestClassifier
model = RandomForestClassifier()
visualizer = ClassificationReport(model, size=(1080, 720))
visualizer.fit(X_train, y_train)
visualizer.score(X_test, y_test)
visualizer.poof()
ELI5
ELI5 — еще одна визуальная библиотека, удобная для устранения ошибок в моделях и для объяснения прогнозов. Она совместима с самыми популярными Python-библиотеками ML: scikit-learn, XGBoost и Keras. При помощи ELI5 посмотрим на важность признаков нашей модели:
import eli5
eli5.show_weights(model, feature_names = X.columns.tolist())
По умолчанию метод show_weightsиспользует gain, чтобы рассчитать вес, но можно вычислить другие характеристики, добавив аргумент importance_type. Для определения оснований прогноза можно использовать use_prediction.
from eli5 import show_prediction
show_prediction(model, X_train.iloc[1], feature_names = X.columns.tolist(),
show_feature_values=True)
LIME
LIME (локально интерпретируемое объяснение, не зависящее от устройства модели) — пакет, используемый для интерпретации прогнозов тех или иных алгоритмов машинного обучения. Lime поддерживает объяснения для индивидуальных прогнозов широкого круга классификаторов. Встроена поддержка scikit-learn.
Будем работать с нашей моделью. Сначала создадим интерпретатор. Он видит набор данных как массив. Имена признаков используются в модели, а имена классов в целевой переменной.
import lime.lime_tabular
explainer = lime.lime_tabular.LimeTabularExplainer(X_train.values, feature_names=X_train.columns.values.tolist(), class_names=y_train.unique())
Создадим лямбда-функцию, использующую модель для прогнозирования на основе имеющихся данных:
predict_fn = lambda x:
model.predict_proba(x).astype(float)
Также используем интерпретатор для расшифровки прогноза. Результат приведён ниже. При помощи Lime можно создать визуализацию, отображающую влияние конкретных признаков на прогноз:
exp = explainer.explain_instance(X_test.values[0], predict_fn, num_features=6)
exp.show_in_notebook(show_all=False)
MLxtend
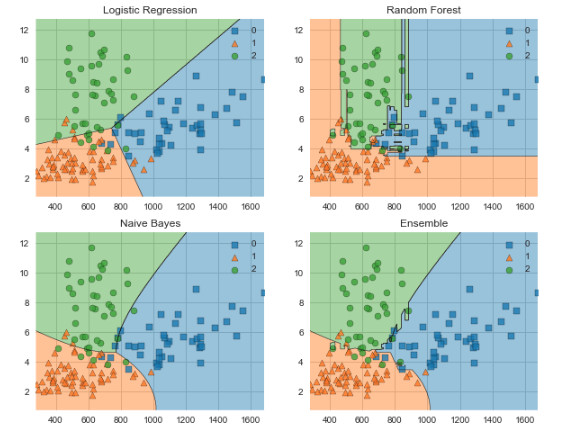
Библиотека MLxtend содержит ряд вспомогательных функций для машинного обучения. Например, для StackingClassifier и VotingClassifier, эволюции модели, извлечения признаков, для разработки и для визуализации данных. С помощью MLxtend и сравним границы решения VotingClassifier и входящих в его состав классификаторов:
Необходимые пакеты представлены ниже:
from mlxtend.plotting import plot_decision_regions
from mlxtend.classifier import EnsembleVoteClassifier
import matplotlib.gridspec as gridspec
import itertoolsfrom sklearn import model_selection
from sklearn.linear_model import LogisticRegression
from sklearn.naive_bayes import GaussianNB
from sklearn.ensemble import RandomForestClassifier
Данная визуализация обрабатывает одновременно только два признака, поэтому создадим массив, который будет содержать признаки proline и color_intensity. Они имеют наибольший вес среди всех остальных, как было выяснено в процессе работы с ELI5.
X_train_ml = X_train[['proline', 'color_intensity']].values
y_train_ml = y_train.values
Теперь создадим классификаторы и обучим их на тренировочных данных, чтобы получить визуализацию границ решений. Ниже показаны код и его вывод.
clf1 = LogisticRegression(random_state=1)
clf2 = RandomForestClassifier(random_state=1)
clf3 = GaussianNB()
eclf = EnsembleVoteClassifier(clfs=[clf1, clf2, clf3], weights=[1,1,1])
value=1.5
width=0.75
gs = gridspec.GridSpec(2,2)
fig = plt.figure(figsize=(10,8))
labels = ['Logistic Regression', 'Random Forest', 'Naive Bayes', 'Ensemble']
for clf, lab, grd in zip([clf1, clf2, clf3, eclf],
labels,
itertools.product([0, 1], repeat=2)):
clf.fit(X_train_ml, y_train_ml)
ax = plt.subplot(gs[grd[0], grd[1]])
fig = plot_decision_regions(X=X_train_ml, y=y_train_ml, clf=clf)
plt.title(lab)
Перевод статьи Rebecca Vickery: Python Libraries for Interpretable Machine Learning
Комментарии